GPT News anonymizer
- 3 mins read
I’m using at home my own server to run gpt models. Without cost I can do funny and stupid things. This one run a pipeline of tasks to anonymize news, critics, sumarize, extract names, places, products, etc.
First I get the entries from google trends
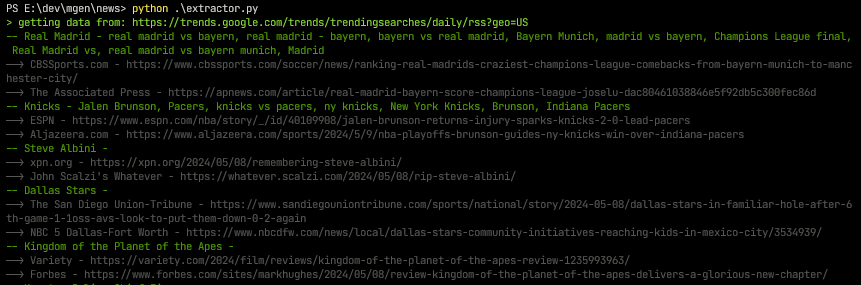
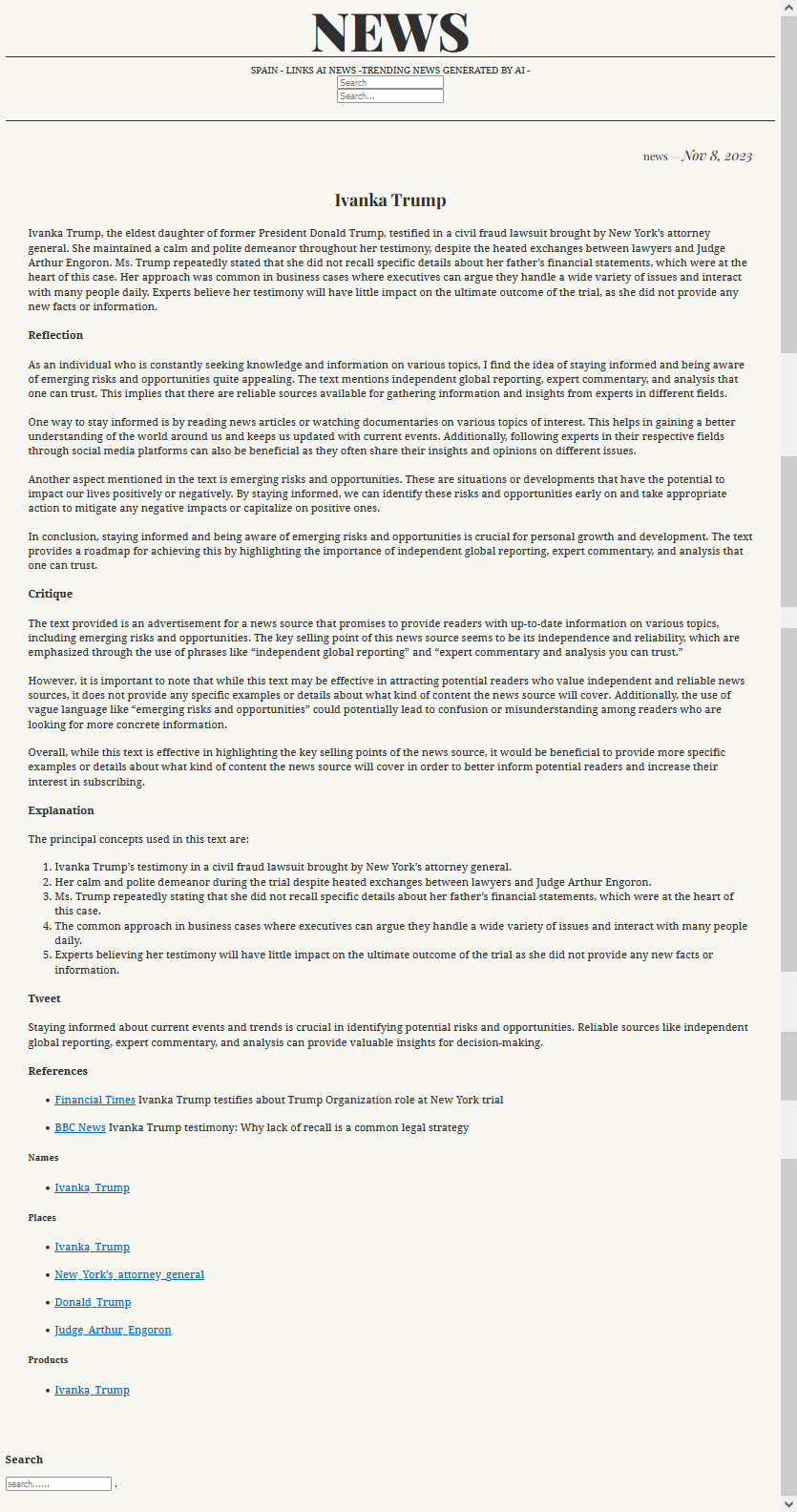
Then I use the GPT model to generate the news.
With this I can generate my own “News Corporation”
The pipeline is like this:
TASKS = [
{
"task": "Write an article centered in the main text idea, discard authors, editors and any non-relevant information. Response must be only the text. Using this:\n",
"input": "",
"output": "clean",
},
{
"task": "Write an article, with the following text. Discard any non-relevant information. Response must be the plain text. ",
"input": "clean",
"output": "article",
},
{
"task": "Do a summary with the main idea for this text:",
"input": "article",
"output": "summary",
"cleaner": "clean_summary",
},
{
"task": "Write a critic about this text:",
"input": "article",
"output": "critics",
},
{
"task": "Write a reflection about this text:",
"input": "article",
"output": "reflection",
},
{
"task": "Summarize in one or two lines this text:",
"input": "summary",
"output": "tweet",
},
{
"task": "Discard any non-relevant information. Write a wide final version of the article: ",
"input": "text",
"output": "final",
},
{
"task": "Explain pricipal concepts used in this text: ",
"input": "final",
"output": "explanations",
},
{
"task": "Get a list of people's names used as comma separated values in this text:",
"input": "final",
"output": "names",
"cleaner": "clean_categories"
},
{
"task": "Get a list of cities, countries or places as comma separated values used in this text:",
"input": "final",
"output": "places",
"cleaner": "clean_categories"
},
{
"task": "List product's or brands as comma separated values in this text:",
"input": "final",
"output": "products",
"cleaner": "clean_categories"
},
{
"task": "Categorize the text as news, sports, entertainment, politics etc.. comma separated values. Use this text:",
"input": "summary",
"output": "topics",
"cleaner": "clean_categories"
},
]
Note that the input of a task may be the output of another task, and the output of a task may be the input of another task. Optionally, a cleaner function can be used to clean the output of a task before using it as input for another task.
Timming
INFO: 10.10.10.1:55154 - "POST /v1/completions HTTP/1.1" 200 OK
Llama.generate: prefix-match hit
llama_print_timings: load time = 548.00 ms
llama_print_timings: sample time = 9.21 ms / 16 runs ( 0.58 ms per token, 1737.05 tokens per second)
llama_print_timings: prompt eval time = 421.49 ms / 561 tokens ( 0.75 ms per token, 1331.00 tokens per second)
llama_print_timings: eval time = 263.76 ms / 15 runs ( 17.58 ms per token, 56.87 tokens per second)
llama_print_timings: total time = 2502.76 ms